






인간은 사진을 보고 이를 어떤 장면인지 설명할 수 있다. 하지만 인간에겐 이런 간단한 일도 컴퓨터에겐 무척 어려운 일이다. 하지만 구글은 기계학습 시스템을 이용해 사진을 한 번 보면 자동으로 상황을 설명하는 자막을 생성하는 마치 인간과 같은 능력을 가진 시스템 개발에 성공했다.
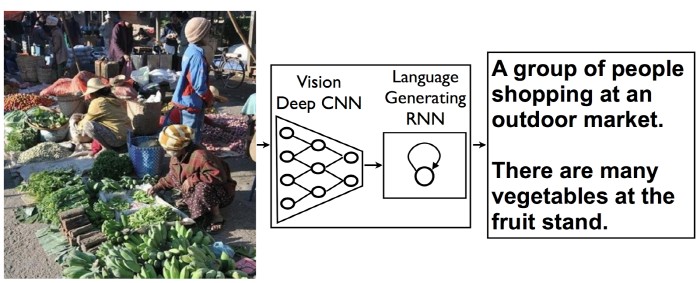
최근 연구는 물체 검출이나 분류, 라벨링 등 크게 기술이 발전했다. 하지만 인간처럼 복잡한 상황을 간결하게 설명하려면 깊은 표현의 폭과 다양한 물체를 정확하게 인식하고 이를 자연스러운 말로 표현하는 일이 필요하다. 사람의 눈을 대신해 이미지를 인식하고 위치와 분류, 측정, 검사 등을 실시하는 시스템을 머신 비전이라고 한다. 이런 머신 비전과 복잡한 상황도 적절하게 설명할 수 있는 자연어 처리 시스템을 결합하면 멋진 시스템 구현을 기대할 수 있다. 다만 여기에는 인간의 뇌 기능을 대신하는 가상 시뮬레이션 신경망인 RNN(Recurrent neural network)이 필요하다. RNN을 이용해 이미지에서 문장이나 단어를 생성하고 사진에 캡션을 붙일 수 있는 것이다.

먼저 CNN(Convolutional Neural Network) 알고리즘을 이용해 화상을 인식해 분석한다. CNN을 이용한 화상 인식 알고리즘은 마지막 단계에서 사진 속 물체가 무엇인지 대략적인 전망을 해 결정하는 작업을 진행한다. 하지만 구글이 만든 시스템은 이를 대신해 언어 생성을 위한 RNN을 추가, 대량으로 생성한 이미지에 대한 정보를 RNN에 공급한다. 이렇게 하면 기존 이미지 인식 알고리즘으로 생성한 데이터를 언어 생성을 위한 RNN에 활용할 수 있게 된다.
이 시스템에 다양한 이미지를 인식하게 한 다음 캡션을 생성하면 시스템은 기계학습을 통해 더 정확한 캡션을 붙일 수 있게 된다. 구글 연구팀은 오픈 데이터베이스 이미지를 처리하도록 해서 캡션 품질을 끌어올리는 데 성공했다.
이 기술은 이미지 인식 시스템과 자연어 처리 시스템을 결합한 것이다. 시스템은 미래에는 시각 장애가 있는 사람이 영상이나 이미지를 볼 때 도움을 주고 인터넷 회선 속도가 느린 곳에선 사진보다 먼저 텍스트로 상황을 설명해주는 등 이미지를 보완하는 역할을 할 것으로 기대된다. 심지어 구글 이미지 검색 정확도를 높이는 데에도 도움이 될 것으로 보인다.
전자신문인터넷 테크홀릭팀
최필식기자 techholic@etnews.com
