






딥러닝 시장이 뜨겁다. 가트너는 2014년 세계 IT 시장 10대 주요 예측 중 딥러닝을 포함했다. 빌게이츠 마이크로소프트 창업자 겸 기술 고문은 한 인터뷰에서 만일 지금 컴퓨터 과학을 공부하는 학생이라면 어떤 분야에 몰두했을 것 같냐는 질문에 딥러닝을 들기도 했다.

딥러닝은 컴퓨터가 여러 케이스를 조합해 자율적으로 학습하는 구조다. 인간의 뇌 같은 인식 구조와 유사한 형태의 학습을 통해 신경망으로 불리는 인공지능을 구축하는 것. 쉽게 말하자면 딥러닝은 인간의 사고방식을 컴퓨터에 적용하려는 것이다. 음성인식이나 자연어 처리, 검색 품질 등 다양한 작업에 접목할 수 있다. 요즘 주목받는 자동 운전이나 자율 로봇의 움직임 같은 것도 딥러닝을 필요로 하는 분야 가운데 하나다.
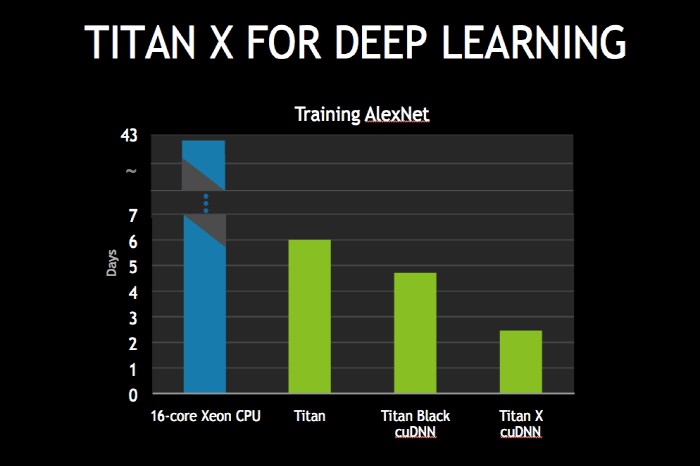
구글이나 바이두, 마이크로소프트, 페이스북 같은 해외 기업은 물론 네이버와 다음카카오 등 국내 업체도 딥러닝을 적용하고 있다. 네이버의 경우 네이버 딥러닝랩을 통해 음성 인식을 테스트하는 한편 뉴스 요약 서비스, 이미지 분석 등에 딥러닝 알고리즘을 적용하고 있다. 구글도 딥러닝에 열심이다. 구글은 인공지능 업체인 딥마인드를 지난 2014년 1월 4억 달러에 인수한 바 있다.

딥러닝을 언급할 때 함께 따라오는 말이 바로 머신러닝(Machine Learning), 기계학습이다. 기계학습이란 사람의 학습 능력을 본뜬 인공지능 체계를 말한다. 인공지능 개발을 위한 기본 개념으로 인간의 지식이나 정보, 경험 등을 컴퓨터에 넣어서 분석하는 것이다. 분석 데이터를 통해 머신러닝 체계를 구축하게 된다. 엔비디아 역시 3월 17∼20일까지 실리콘밸리 산호세컨벤션센터에서 열린 GTC(GPU Technology Conference) 2015 기간 중 딥러닝에 상당 시간을 할애했다. 그렇다면 엔비디아가 딥러닝에 주목하는 이유는 뭘까.

엔비디아 입장에서 중요한 건 GP GPU(General Purpose Graphics Processing Units), 그러니까 GPU 병렬 컴퓨팅이다. GP GPU는 GPU를 연산에 활용하는 기법이다. GPU 내부에 잇는 수많은 코어를 병렬로 여러 개 연결해서 한 번에 움직이게 하는 것. 이런 GPU 병렬 프로그래밍을 위해 쓰이는 표준 격인 이종 플랫폼 병렬처리 언어가 오픈CL(OpenCL)이다.
엔비디아는 이런 오픈CL과 비슷한 엔비디아만의 전용 GPU 병렬 프로그래밍 언어인 쿠다(Cuda)를 밀고 있다. 쿠다는 엔비디아의 다양한 게임웍스 모듈을 포함하고 있다.
엔비디아가 쿠다를 미는 이유는 엔비디아가 기본적으론 GPU를 많이 팔아야 성장하는 회사라는 점이 작용한다. 물론 엔비디아는 쿠다로 구현한 병렬 프로그래밍이 훨씬 좋은 성능과 효율을 낸다고 말한다. 실제로 쿠다의 가장 큰 장점은 성능에 있기도 하다.
하지만 그보다 더 이면에는 오픈CL이 업계 공용인 반면 자사의 전용 병렬 프로그래밍 언어를 이용하면 결국 엔비디아의 GPU 성장으로 이어질 수 있다는 포석이 자리 잡고 있다. 엔비디아는 구글 브레인이나 이미지, 영상 코덱 처리 등 다양한 작업을 쿠다로 만들어 GPU 시장 확대와 성장을 노린다. GTC는 이런 점 때문에 지난 1년 동안 쿠다로 구현한 애플리케이션은 어떤 게 나왔고 사례는 어떤 게 있었는지 확인하는 자리이기도 하다.
딥러닝(Deep Learning), 머신 러닝 역시 이런 맥락에서 이해할 수 있다. 엔비디아는 지난해와 마찬가지로 올해도 머신러닝을 강조하고 있다. 머신러닝을 CPU만이 아닌 GPU로 병렬 처리하면 훨씬 빠르게 구현할 수 있다는 것이다.
딥러닝은 GPU의 킬러 애플리케이션 중 하나가 될 가능성이 높다. GPU가 딥러닝에 주목하는 이유는 딥러닝 과정 자체가 병렬 연산 덩어리 같은 것이기 때문. CPU에 병렬 연산을 잘하는 GPU를 요구하는 적당한 대상이라는 얘기다.
주요 IT기업도 딥러닝에 공을 들이고 있다. 바이두는 지난 1월 딥러닝 슈퍼컴퓨터인 밍와(Minwa)를 개발했다고 밝혔다. 이 슈퍼컴퓨터는 딥러닝 알고리즘에 최적화한 것. 밍와는 36노드로 이뤄져 있다. 노드마다 6코어 인텔 제온 E5-2620 2개와 엔비디아 테슬라K40M GPU 4개, 56Gbps FDR 인피니밴드 등으로 이뤄져 있다. GPU의 부동소수점 연산 성능은 4.29TPLOS다. 밍와에 들어간 GPU 개수는 모두 144개다. 밍와의 당시 이미지 인식 에러율은 5.98%로 구글이 세운 6.66%보다 뛰어나다. 사람의 에러율은 5.1%로 알려져 있다.
딥러닝을 대규모 데이터 분석을 필요로 한다. 고성능 GPU는 이런 문제를 해소할 수 있는 방법 가운데 하나다. 딥러닝이 각광을 받게 된 것도 복잡한 구조를 처리할 수 있는 뛰어난 컴퓨팅 파워, 연산 능력이 생겼기 때문이기도 하다. 딥러닝은 복잡한 신경망 구조를 지니고 있는데 이를 뒷받침할 만한 컴퓨팅 파워가 등장한 것이다.
미국 실리콘밸리 산호세컨벤션센터에서 열린 GTC(GPU Technology Conference) 2015 기간 중인 3월 19일(현지시간) 키노트에 나선 앤드류 응(Andrew Ng) 바이두리서치 책임자는 2007년까지만 해도 CPU 커넥션은 100만이었지만 2008년 GPU 커넥션은 10배 높은 1,000만에 달했다고 밝혔다. 여기에 2011년 클라우드로 확장되면서 CPU 커넥션은 10억까지 확대됐다고 밝혔다. 다시 2015년에는 GPU를 통해 1,000억으로 늘어났다. 그는 GPU 하나로 딥러닝을 처리할 경우 212시간이 걸리던 게 GPU를 16개로 늘리면 20시간, 32개면 다시 8.6시간으로 줄어든다고 설명했다.
얼굴 인식 에러율의 경우 마이크로소프트는 3.67%, 페이스북 1.63%, CUHK 0.53%, 구글 0.37%인 반면 바이두는 0.15%에 불과했다고 밝혔다. 6,000개 이미지 테스트 샘플 중 에러는 9개에 불과한 수준이라는 설명인 것.
바이두는 현재 음성 인식과 딥이미지(Deeep Image)라고 불리는 화상 인식, 자연어 처리 연구 등을 진행하고 있다. 지난 2014년에는 바이두판 구글글라스 격인 바이두 아이(Baidu Eye)를 선보이기도 했다. 본체 좌우에 있는 카메라를 이용해서 사물은 인식한 다음 관련 정보를 음성으로 제공하는 것이다. 그는 바이두의 음성 인식 에러율이 애플이나 마이크로소프트, 페이스북, 구글보다 더 낮다고 밝혔다.
앤드류 응은 현장에서 바이두의 음성 인식 성능을 시연하기도 했다. 비교 대상과의 테스트에서 바이두의 음성 인식을 통한 텍스트 변환 성능은 잡음을 높인 상태에서도 상당한 인식률을 보여 눈길을 끌었다. 앤드류 응은 음성인식 기술이 웨어러블과 자동차, 가정용 전자기기 등 사물인터넷 시장을 바꿔놓을 것이라고 말한다. 그는 이렇게 딥러닝의 기회가 이미지와 음성, 행동 패턴 등에 있다는 점을 강조했다.
전자신문인터넷 테크홀릭팀
이석원기자 techholic@etnews.com