






카디날정보기술은 빅데이터 전문기업이다. 지난 2010년 김지연 대표 취임 이후 공개SW인 몽고DB를 바탕으로 4∼5년 전부터 IT 업계에 화두로 떠오른 빅데이터에 주목했다. 단순 SI가 아니라 기술 개발에 주력해 몽고DB 사이트에 자체 개발한 몽고버드(Mongobird)와 몽고아울(Mongogwl) 등 몽고DB 모니터링 툴을 공개하기도 했다. 2013년 4월에는 몽고DB를 개발한 몽고DB Inc와 국내에선 유일하게 SW 공식 파트너십을 체결하는 등 이 분야에서의 전문성을 인정받고 있다.
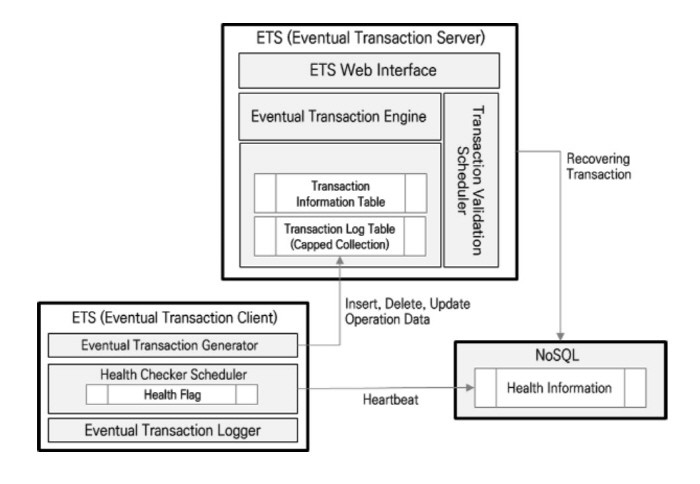
◇ RDB+몽고DB, 모나DB가 탄생한 이유=카디날정보기술이 직접 개발해 몽고DB 사이트에 공개한 몽고버드와 몽고아울은 라이선스는 물론 공개SW로도 공개하고 기트허브에도 소스를 올려놓은 상태다. 몽고DB 데이터베이스 데몬 전체를 모니터링할 수 있는 전체 모니터링 시스템이다. 몽고아울은 그 중 데몬 하나에 대해 실시간 모니터링을 할 수 있는 것. 이 회사 이완희 차장은 이들 모니터링툴을 개발한 이유로 “운영 뿐 아니라 NoSQL 쪽은 계속 보면서 개발하고 수정하는 최적화 과정이 많이 필요하다”는 점을 들었다.
카디날정보기술은 당시 LG나 넥슨 등 주요 기업에 구축이나 컨설팅 등을 진행해왔다. 그런데 이런 와중에 몽고DB를 쓰다 보니 몽고DB를 쓰면서 생기는 당연히 요구사항이 생긴다. RDB만 계속 써왔는데 RDB에서 쓰이던 기능이 NoSQL에선 해당 기능이 없으니 불편하고 당황스러웠던 것.
이 차장은 “가장 큰 요구사항은 RDB는 SQL을 이용한 트랜잭션 처리가 되는데 몽고DB는 스키마가 없는 NoSQL이다 보니 자체 쿼리를 써야 하는 등 기존에 쓰던 것과 다르다는 게 힘들다는 불만이 있었다”는 점이었다고 말한다. 또 기존에 사용하던 서비스가 있으면 일부를 몽고DB로 바꾼다고 하면 해당 쿼리를 모두 바꿔야 하는 문제가 생겼다. 작업량이 많아지고 쓸데없는 부하가 늘어나는 것도 물론이다.

모나DB는 장애가 발생해도 마스터가 복구될 때까지 트랜잭션을 유지한다. 기존 몽고DB에선 지원하지 않는 트랜잭션 지원 기능을 갖춘 것이다.
결국 카디날정보기술은 트랜잭션 처리를 어떻게 할지 고민하다가 직접 ‘NoSQL 데이터베이스를 위한 결과적 트랜잭션 처리 방법’에 대한 특허를 냈다. NoSQL에서도 트랜잭션 처리를 할 수 있게, SQL을 쓸 수 있게 할 수 있게 만든 것.
그런데 트랜잭션이 되니 SQL로 RDB처럼 다 쓸 수 있는 것 아니냐는 새로운 요구가 생겼다. 그래서 이런 고객 요구를 해결하기 위해 몽고DB는 대용량으로만 쓰고 분산이 잘 되는 RDB를 선택해서 둘을 함께 합치면 성능이 좋은 게 잘 나오겠다는 생각으로 연구를 했고 그 결과로 탄생한 게 바로 모나DB다.
이렇게 탄생한 모나DB는 대용량 데이터를 저장하기 위한 문서 기반 수평적 확장이 가능한 NoSQL 데이터베이스로 공개SW인 몽고DB를, SQL 표준 질의나 분산 병렬 쿼리 처리를 위한 관계형 데이터베이스인 PostgreXC를 결합한 형태를 취하고 있다. 분산이 잘 되는 RDB인 PostgreXC에 몽고DB를 합쳐놓은 것이다. 여기에 속도 보장 등을 위해 특허 2개를 더 얹어서 속도와 안정성, 확장성을 보장하게 했다는 설명이다.
이렇게 탄생한 모나DB는 몽고DB보다 빠른 질의 처리가 가능해졌다. 그 뿐 아니라 카디날정보기술은 특허를 하나 더 보탰다. 데이터 저장 공간을 무한 확장할 수 있도록 한 것이다. 운영하다 보면 가장 큰 고민 가운데 하나는 어떻게 하면 서비스 중단 없이 디스크를 확장할 것인가다. 모나DB는 서버에서 서비스를 내리지 않은 상태에서 레이드 구성을 깨지 않은 채 추가로 얼마든지 디스크를 확장할 수 있다.
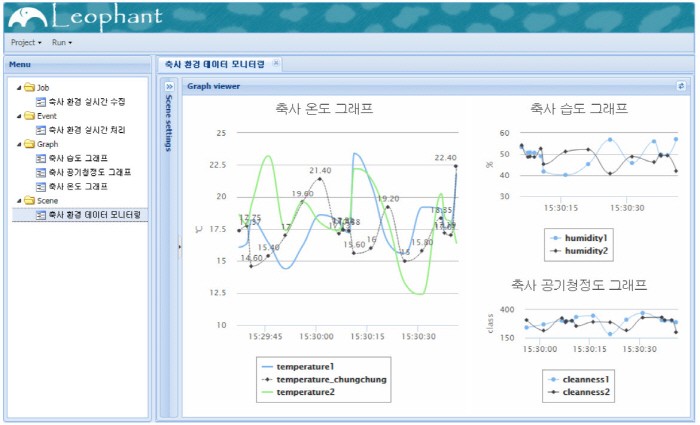
레오펀트의 실행 화면. 레오펀트는 빠르게 수집하는 대용량 데이터, 패스트 데이터를 대상으로 한 실시간 처리 및 분석 플랫폼이다.
현재 방식은 2TB에 1TB를 끼운다면 처음부터 다시 3TB를 대상으로 마이그레이션을 다시 해야 한다. 하지만 모나DB의 시스템은 mFS(monaDB File System)을 이용, 기존 2TB는 그대로 두고 추가로 1TB만 구성하는 간편한 추가 방식을 지원한다.
성능도 마찬가지. 이완희 차장은 “PostgreSQL을 이용한 시스템과 견주면 한 노드당 2.4배, 노드 수를 2개로 늘리면 4.5배까지 빠른 성능을 기대할 수 있다”고 설명했다.
◇ 레오펀트 “빅데이터 트렌드 변화 읽은 플랫폼”=카디날정보기술이 모나DB를 직접 개발하게 된 데에는 이 회사가 중점을 두는 빅데이터 저장을 위한 고민을 해결하기 위한 것이기도 하다. 빅데이터에 대한 분야는 크게 저장, 분석, 관리, 컨설팅 4가지로 나눌 수 있다. 국내에서 가장 많은 쪽은 분석이다. 분석에 대한 쏠림 현상이 강한데 눈에 가장 띄게 결과가 나오는 것도 한 몫 한다. 하지만 근본적인 것에 집중했다. 분석을 하려면 데이터를 어딘가에는 저장해야 한다.
김지연 대표는 이런 점에서 “국내에선 빅데이터가 되면 내일부터 바로 수익이 날 것이라는 환상이 있었다”면서 이런 이유로 “저장은 어딘가에 되겠지라는 생각에 곧바로 분석에 들어가 버린다”고 말한다. 저장하는 방법이나 수집 방법 등이 전부 천차만별이다. 지금 시점에서 거품이 빠지면서 국내에서도 분석에서 반대로 근본적인 저장에 대한 고민을 하고 있다.
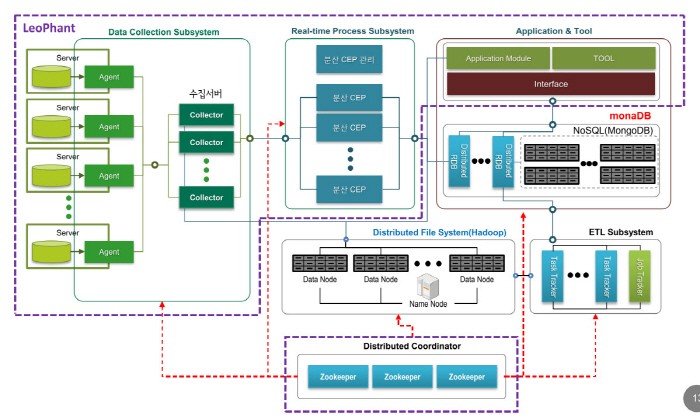
레오펀트 아키텍처 구조도
이렇게 트렌드가 분석에서 다시 저장과 수집 쪽으로 돌아서는 한편 빅데이터 자체에 대한 정의도 바뀌고 있다. 빅데이터를 스마트 데이터와 패스트 데이터로 나누는 것이다.
스마트 데이터란 쉽게 말해 현업에선 필요한 건 정확한 품질이 보장되는 데이터만 필요한 것. 이런 개념에서 필요한 부분에서 걸러내고 정제된 데이터만 쓰는 취지로 만들어진 것이다. 스마트 데이터에는 정확성과 행동성, 민첩성이라는 3가지 요소가 들어간다.
패스트 데이터는 데이터를 수집한 다음 저장하고 한참 있다가 뽑아서 무슨 소용이 있냐는 생각에서 시작한 것. 예를 들어 금융이나 로그 같은 데이터는 저장해서 분석할 필요보다는 곧바로 내용을 봐야할 필요성이 더 크다. 요즘 유행하는 사물인터넷(IoT) 관련 센싱도 마찬가지다. 실시간성이 더 중요해지고 있는 것이다. 패스트 데이터는 실시간으로 빠르게 들어오는 대용량 데이터가 패스트 데이터다.
이런 패스트 데이터에 대한 처리에 대한 고민의 결과물이 바로 자체 개발한 플랫폼인 레오펀트(LeoPhant)다. 레오펀트는 초당 수천에서 수만 번씩 발생하는 대용량 데이터를 실시간 처리하는 분산 플랫폼이다.
카디날정보기술 측은 레오펀트를 2세대 빅데이터 플랫폼이라고 부른다. 국내에선 ‘빅데이터=분석=하둡’이라는 공식이 많았다. 하둡을 많이 썼다. 하둡을 정말 잘 쓰면 문제가 없지만 그게 아니라 어설프게 쓰면 느리다는 궁금증만 갖고 끝난다. 하둡은 배치 시스템이어서 잘 모르면 느릴 수밖에 없다. 잘 쓰려면 하둡의 장점에 맞게 원하는 로직을 만들어서 결과를 도출해야 한다. 로직을 만들려면 하둡을 쓰려는 회사에서 로직도 고민해야 하는데 그런 것 없이 그냥 개발사에 요구만 하는 경우가 많다. 또 배치 시스템에 대한 보완적인 요소에 대한 고민도 함께 반영한 게 레오펀트다. 레오펀트에 플랫폼으로 하둡을 함께 적용해서 쓸 수도 있다. 김지연 대표는 “레오펀트가 즉시적 결정, 그러니까 비즈니스적 인사이트를 위해 만든 것”이라고 말한다.
레오펀트에도 공개SW를 적극 활용한 건 물론이다. 대용량 데이터를 실시간으로 수집하기 위해 공개SW 메시지 큐 시스템인 Kafka를 썼고 CEP(Complex Event Processing) 환경에서 이런 대용량 실시간 분석 처리를 위해 실시간 분석 분산 시스템 공개SW인 Storm을 곁들였다. 여기에 데이터 시각화 기능을 위해 Redis와 분석 처리를 위한 RDB로 mariaDB를 썼다. 공개SW를 활용한 패스트 빅데이터 처리를 위한 플랫폼인 것이다.
레오펀트는 기본에 충실하게 만든 아키텍처여서 어디에나 접목하기 쉽다는 장점이 있다. 당연히 패스트 데이터에 대한 빠른 처리 능력도 갖췄다.
레오펀트는 성능 뿐 아니라 가격적인 면에서도 강점을 띄고 있다. 모나DB와 레어펀트 자체는 모두 공개SW를 이용해서 만든 것이다. 다만 특허 기술을 포함한 만큼 라이선스 형태로 오픈할 예정이지만 어떤 식으로 갈지 여부는 결정하지 않은 상태다. 하지만 이완희 차장은 보통 성능이 비슷한 5억원짜리 시스템과 비교하면 10분의 1 수준에 불과하다고 설명한다.
오라클RAC 같은 쪽과 비교하면 장비 등 시스템 구성에 따라 차이가 있겠지만 10∼15배 차이가 난다고 말한다. 그 뿐 아니라 오라클RAC의 경우 노드를 확장하면 성능 저하가 발생할 수 있지만 레오펀트는 이런 염려가 없다. 간혹 레오펀트를 Splunk와 비교하기도 하는데 이 차장은 “Splunk가 툴이라면 레오펀트는 플랫폼인 만큼 엄밀히 얘기해 다르다”고 말한다. 굳이 비교를 한다면 Splunk는 DB를 검색 기반 인덱싱 처리를 하는 반면 레오펀트는 NewSQL, 시각화만 해도 Splunk는 저장 후 질의 처리를 하지만 레오펀트는 라이브 시각화가 가능하다. 그 밖에도 많은 차이가 있지만 Splunk는 주로 BI 전문가 대상이지만 레오펀트는 빅데이터 서비스 개발자를 대상으로 한 것이다. 결정적 차이라면 Splunk가 폐쇄적인 반면 레오펀트는 공개SW를 활용할 수 있다는 점이다.
◇ “사물인터넷 궁합 잘맞는 공개SW 기반 플랫폼”=이렇게 공개SW를 기반으로 탄생한 모나DB와 레오펀트가 강점을 가질 수 있는 분야는 어디일까. 당연히 데이터가 많은 쪽이다. 로그나 센싱 데이터를 DB화해서 질의나 분석을 위한 시스템은 물론 증권이나 금융, 제조업 같은 분야에 활용할 수 있다. 게임이나 포털처럼 동접(동시접속)이 많은 분야도 마찬가지다. 모나DB가 갖춘 확장성과 안정성이 도움이 된다는 설명이다. 또 클라우드형 DB 시스템이나 멀티미디어 데이터 같은 분야도 모나DB가 강점을 띤다.
물류 같은 곳도 대표적인데 실제로 카디날정보기술은 모나DB와 레오펀트를 만들자마자 ETRI와 함께 건강 검진 데이터를 바탕으로 한 빅데이터 형태 플랫폼을 시범 서비스 형태로 구축하는 사업을 진행 중이다. 김 대표는 그 뿐 아니라 헬스케어와 스마트시티, 농장물처럼 센싱 데이터를 이용한 사물인터넷 분야도 예가 될 수 있다고 말한다. 이 차장은 정부 차원에서 최근 정부 3.0을 선언했는데 이 일환으로 진행하는 스마트 팩토리의 경우에도 공장 데이터를 바탕으로 한 실시간 모니터링을 대상으로 모나DB와 레오펀트가 잘 어울릴 만한 대상이 될 것이라고 밝혔다. 김 대표는 어디든 어울릴 수 있지만 요즘 트렌드에 맞춰 생각해보자면 한마디로 “사물인터넷과 융합한 분야”가 될 것이라고 말했다.
카디날정보기술 김지연 대표는 공개SW의 가장 큰 장점을 묻는 질문에 “몽고DB가 공개SW가 아니었다면 모나DB는 없었을 것”이라는 말로 기술 발전이 가장 큰 의미가 있다고 답했다.
카디날정보기술은 현재 레오펀트와 모나DB 차기 버전을 준비하고 있다. 더 편한 수집이나 기본 탬플릿을 이용한 시각화, GIS 연동 같은 기능을 추가한 차기 버전을 내년 3월말까지는 선보일 예정인 것. 몽고DB 시절부터 전문 기술 블로그를 운영해 개발자를 위한 정보 공유를 했듯 모나DB와 레오펀트 등의 정보를 위한 기술 블로그 운영도 할 계획이다. 또 12월 3∼4일까지 미래창조과학부가 주최하고 정보통신산업진흥원이 주관하는 2014 상용소프트웨어 전시회(https://swexpo.kr)에도 참여한다.
※ 이번 공개SW 활용 성공사례는 테크홀릭과 정보통신산업진흥원 공개SW 역량프라자가 공동으로 발굴한 기사(http://www.oss.kr/oss_repository10/604086)다.
전자신문인터넷 테크홀릭팀
이석원기자 techholic@etnews.com