






멀티모달(Multi-modal) 기술은 인공지능(AI) 시대를 촉진하는 부스터 역할을 하고 있다. 말 그대로 다양한 모달리티(Modality, 의사소통 채널)를 동시에 인식하는 AI 모델을 일컫는다. 텍스트 뿐 아니라 이미지, 음성, 제스쳐, 표정 등 여러 모달리티를 받아들이고 사고할 수 있다. 이는 곧 AI가 인간과 더욱 자연스럽게 소통할 수 있게 된다는 것을 의미한다.
전 세계적으로 멀티모달 연구는 활발하게 전개되고 있다. 메타(전 페이스북)는 음성, 영상 데이터 기반의 멀티모달 연구를 위해 'MUGEN' 데이터셋을 공개했으며, 인스타그램 릴스 추천 기능에도 멀티모달 기술을 적용했다. 구글의 경우, MUM(Multitask Unified Model, 멀티태스크 통합 모델)과 멀티모달 기술을 접목해 구글 검색 서비스 개편을 시작했다. 오픈AI는 텍스트-이미지 생성 모델인 '달리(DALL-E) 2' 서비스를 공개한 바 있다. 이 서비스를 통해 사용자들이 직접 생성한 이미지가 트위터에 공유되면서 DALL-E 2의 인기가 높아지고 있다. 또한 엔비디아에서는 멀티모달 기술 기반의 페인팅 툴인 '고갱2(GauGan2)'도 공개했다.
국내 테크기업들도 멀티모달 AI 기술 개발에 집중하고 있다. 카카오브레인은 원하는 이미지를 텍스트로 입력하면 무제한으로 이미지를 생성해주는 이미지 생성 모델 '칼로(Karlo)'를 개발했다. 향후 다양한 서비스에 적용할 수 있도록 플랫폼화하고 있다. 지난 8월 31일에는 약 7억4000만 개의 이미지-텍스트로 이루어진 데이터셋 '코요'를 공개하며 기술 주도권 확보에 열을 올리고 있다.
LG AI연구원에서 선보인 '엑사원'도 한국어와 영어를 동시에 이해하고 구사하는 이중언어 AI라는 점 외에 텍스트, 음성, 이미지, 영상을 자유자재로 변환할 수 있는 멀티모달형 AI로 평가받고 있다. 언어를 이미지로, 이미지를 언어로 변환하는 기술을 구현했다.
연구 단계를 넘어 서비스 적용도 시도하고 있다. 비주얼아트, 의료, 교육, 커뮤니케이션 분야를 포함한 다양한 산업에서 해당 기술을 활용할 방향을 탐색 중이다. 네이버는 올 4월 멀티모달 검색 엔진인 '옴니서치'를 '스마트렌즈'에 우선 적용했다. 옴니서치는 텍스트, 이미지, 음성 등 각기 다른 입력을 조합해 이해하고, 보다 사용자 의도에 적합한 검색 결과를 제공한다. 예를 들어 하얀색 나이키 운동화 사진을 입력한 후, '유사한 디자인 아디다스' 등을 입력하면 이에 해당하는 검색결과를 보여주는 식이다.
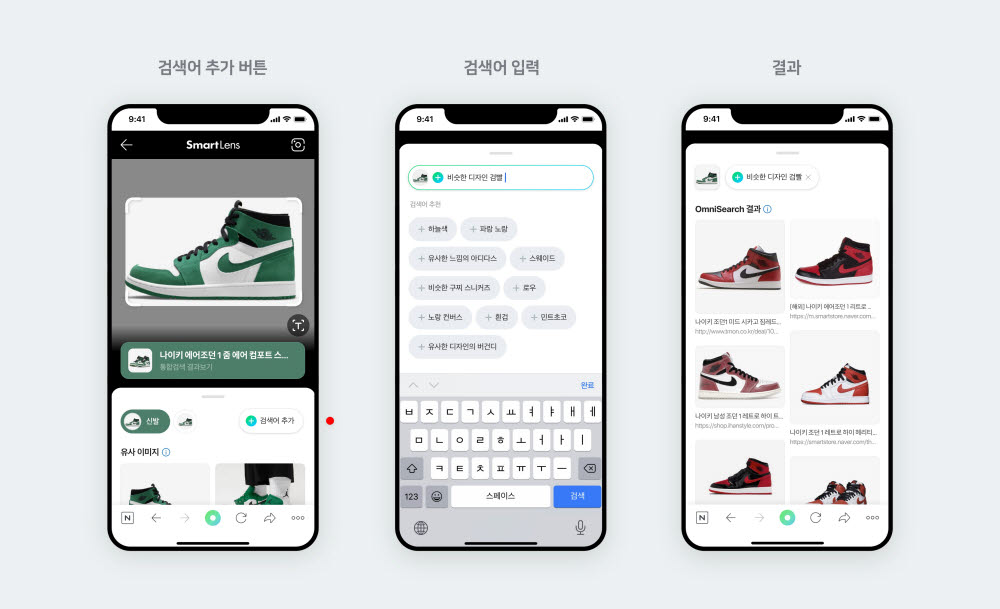
네이버는 옴니서치가 적용된 스마트렌즈를 향후 스니커즈 분야에서 전체 패션 카테고리로 확대할 예정이다. 이후에는 쇼핑, 음식, 식물, 장소 등 더 다양한 주제에 순차 적용할 계획이다.
네이버측은 “옴니서치의 경쟁력은 네이버 생태계에서 생성되는 한국어 기반의 멀티모달 데이터라고 할 수 있다”며 “네이버가 20년 간 지식iN, 블로그, 카페, 웹툰, 쇼핑 등 다양한 서비스를 운영하며 텍스트와 이미지를 동시에 담은 양질의 멀티모달 콘텐츠를 많이 보유할 수 있었기 때문에 향후 이 분야 기술 경쟁력에서도 자신있다”고 말했다.
성현희기자 sunghh@etnews.com


