






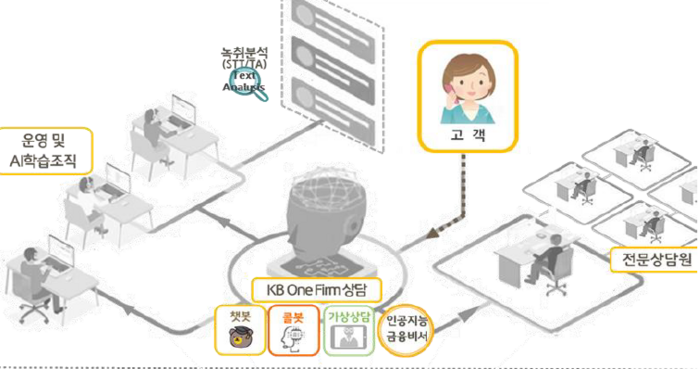
KB국민은행은 금융AI센터를 필두로 인공지능 전환(AX)을 본격화하고 있다. KB STA, KB AI-OCR, 마켓센싱(Market Sensing) 모델 개발 등에 대한 기술 내재화를 하였고, 이후 이미지, 음성, 영상 처리 기술에 대해서도 내재화를 진행하고자 계획 중이다.
대표적인 AI 기술인 KB-STA(State of the art Text Analytics)는 KB국민은행 금융AI센터가 개발하는 AI기반 한국어 텍스트 처리 기술(NLP)의 총칭이다. 한글 문서에 대한 자연어 처리를 위한 도구로, 언어를 기반으로 하는 다양한 정보를 자동화해 처리하기 위해 필요한 기술이다. 지난 2019년부터 금융권 최초 금융특화 AI모델로 개발을 시작했다.
KB STA는 딥러닝 기반 AI 기술 발전에 따라 정확도가 향상되면서 다양한 영역에서 문서에 대한 분석 작업에 사용되고 있다. 한글 형태소 분석, 고유명사 추출, 긍부정 분석, 핵심 키워드/문장 추출, 문서 카테고리 분류, 문장 경계 분석, 주체-객체간 관계 분석 등 다양한 언어 해석 기능을 제공한다.
이밖에 △주어진 질의에 적합한 문서나 문구 형태의 답변을 찾을 수 있는 검색 솔루션 개발 △챗봇이나 콜센터를 통한 고객 문의에 대한 고객 의도 자동 분류 기능 개발 △고객 상담 내역에 기반한 고객 개인화 프로파일링 처리에도 활용된다.
딥러닝 기반의 언어 분석은 PLM(Pre-trained Language Model)을 사용한다. 이 모델은 단어, 문장, 문서를 수치화하여 표현할 수 있고, 이를 통해 유사도 분석 등 다양한 언어 분석 작업을 수행할 수 있다.
PLM은 다양한 문서를 학습 데이터로 사용하여 만들게 되는데, 사용된 문서의 종류나 내용에 따라 언어 모델의 표현력이 달라진다. KB국민은행은 금융 문서에 대한 보다 정확한 분석을 위해 행내에서 자체적으로 금융 도메인 문서에 기반한 언어 모델(PLM)을 구축해 사용 중이다. 이 덕분에 일반 도메인의 언어 모델에 비해 금융 문서에 대한 분석 정확도가 뛰어난 것으로 평가받는다.
실제로 KB-STA에 기반한 AI 검색엔진은 행내 직원 포털사이트에도 'One-KB 검색엔진'으로 적용돼 검색 단계의 50%를 단축하는 데 성공했다.
KB STA는 스캔된 문서나 이미지로부터 문서를 인식하는 'AI-OCR'에도 활용된다. 특정 영역의 의미 정보(이름, 전화번호, 날짜, 주민번호, 기업명 등)를 분석하여 데이터를 추출하는 기술로, 기존의 지정된 위치에서 문자 이미지에 대한 패턴 매칭 방식으로 처리하던 기술에서 더 발전했다. 최신 딥러닝 기술을 이용해 변형에 강하고 인쇄체 문자에 대해서는 사람의 인식 수준에 근접한 성능을 구현했다.
이 기술은 금융권에서 처리하는 다양한 문서에 대한 내용 입력 작업의 효율성을 높여준다. 응용 방식에 따라 사람의 개입을 최소화한 형태의 준-자동화된 처리를 가능하게 한다.
다양한 업무에서 필요로 하는 기술이기 때문에, 각 업무별로 시스템을 구축하기 보다는 공통 플랫폼을 구축하는 방안이 주로 활용된다. 다양한 업무에서 빠르게 적용하고 확장하는 것을 목표로 진화하고 있으며, 올해 12월 말 기준 총 15개의 행내 서비스가 KB AI OCR을 적용해 운영 중인 상태다.
KB국민은행 관계자는 “AI 기술은 빠르게 발전하는 분야로, 시스템 구축 이후에도 데이터의 변화나 요구 사항의 변화, 새로운 기술 적용을 통한 성능 개선을 위해 지속적으로 대응할 필요가 있다”며 “신기술 적용 및 빠른 대응을 위해서는 위부 업체를 통한 업무 처리로는 한계가 있어, 내부 자체 기술 개발능력을 높여 보다 경쟁력 있는 기술 개발 및 적용을 하고자”한다고 설명했다.
이형두 기자 dudu@etnews.com


