






정부가 아래한글문서를 데이터화한다.
그동안 공공분야에서 생성된 방대한 아래한글문서를 데이터화해 학습하고 초거대 인공지능(AI) 활용을 늘리는 게 목표다.
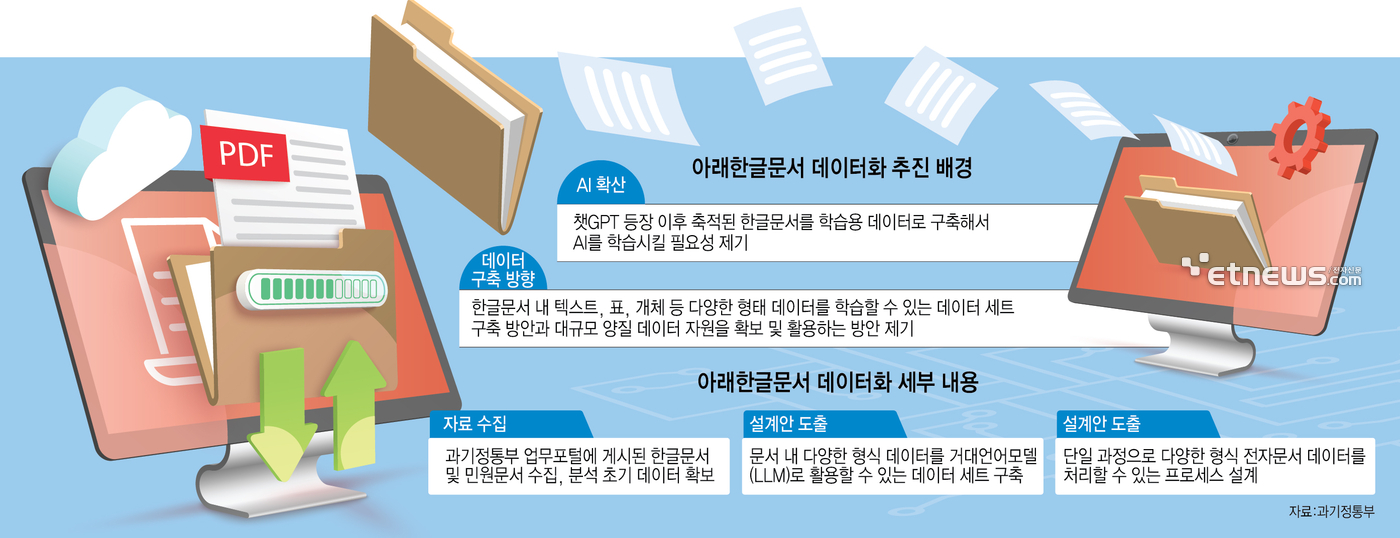
과학기술정보통신부는 아래한글문서 데이터화와 학습 모델 설계 연구 사업에 착수했다. 올해 안으로 초거대 AI 학습과 질의응답에 활용될 다양한 형태 한글문서를 데이터로 변환한다. 또 가공 프로세스 설계안 구성을 위한 자료를 수집하고 설계안을 도출해서 실증까지 끝마칠 방침이다.
이를 위해 과기정통부는 한글문서 전문 지식과 활용 경험을 갖춘 전문가 그룹을 꾸린다. 전자문서 자료 추출에 적합한 도구를 활용하고, 국내외 초거대 AI 학습 방안과 이에 따른 데이터 가공 방법을 조사하는 등 동향을 파악한다. 또 업무 포털에 게시된 외부 공개 가능한 한글 및 민원 문서를 수집해서 분석 초기 데이터를 확보한다.
설계안과 관련해서는 각종 문서 양식을 데이터로 변환하는 안을 도출한다. 구체적으로 국내외 초거대 AI 학습 방안 조사 및 분석 결과에 근거해서 수집된 한글 문서를 학습용 데이터로 변환한다. 문서 내 텍스트, 표 등 다양한 형식 데이터를 거대언어모델(LLM)에 활용 가능한 데이터 세트로 구축하는 방안을 고안한다.
특히 단일 과정으로 다양한 형식 전자문서 데이터를 처리할 수 있는 프로세스를 설계한다. 한글 문서 데이터를 가공한 데이터베이스(DB)와 LLM을 결합한 질의응답 시스템을 구축해서 설계안 적합성을 실증한다.
과기정통부가 아래한글문서 데이터화에 나선 것은 효율적인 지식 관리와 일하는 방식 혁신을 위해서다. 그동안 매해 많은 한글 문서를 지속 생성·저장했지만, 체계적 활용 방안이 부족했다는 평가를 받았다.
특히 오픈AI가 개발한 챗GPT 등장 이후로는 초거대 AI가 민간과 공공에서 적극 활용되고 있다. 이에 따라 축적된 문서 정보 유실을 최소화해서 기존 데이터와 AI 기술을 융합해 체계적으로 활용해야 한다는 목소리가 커졌다.
아래한글문서 데이터화는 정부 업무 효율성을 높이는 한편 공공분야 초거대 AI 확산을 가속화하는 발판이 될 것으로 기대된다.
과기정통부 관계자는 “한글문서 내 대규모 텍스트, 표, 개체 등 다양한 형태 데이터를 학습할 수 있는 데이터셋 구축 방안을 마련하고, 대규모 양질 데이터 자원을 확보해 활용할 것”이라고 밝혔다.
류태웅 기자 bigheroryu@etnews.com


