







 관련 통계자료 다운로드 개인정보 노출 탐지 현황
관련 통계자료 다운로드 개인정보 노출 탐지 현황
오픈AI와 구글, 마이크로소프트(MS), 메타 등 거대언어모델(LLM) 기업의 인공지능(AI) 학습 과정에서 개인정보 보호가 취약한 것으로 드러났다.
개인정보보호위원회는 지난 27일 전체회의에서 오픈AI·구글·MS·메타·네이버·뤼튼테크놀로지스 등 6개 사업자에 대해 개인정보 보호 취약점을 보완하도록 개선권고를 의결했다.
개인정보위가 AI 단계별 개인정보 보호의 취약점을 점검한 결과, 개인정보보보호법상 기본적 요건을 대체로 충족했지만 △공개된 데이터에 포함된 개인정보 처리 △이용자 입력 데이터 등의 처리 △개인정보 침해 예방·대응 조치 및 투명성 등과 관련해 일부 미흡한 사항이 발견됐다.
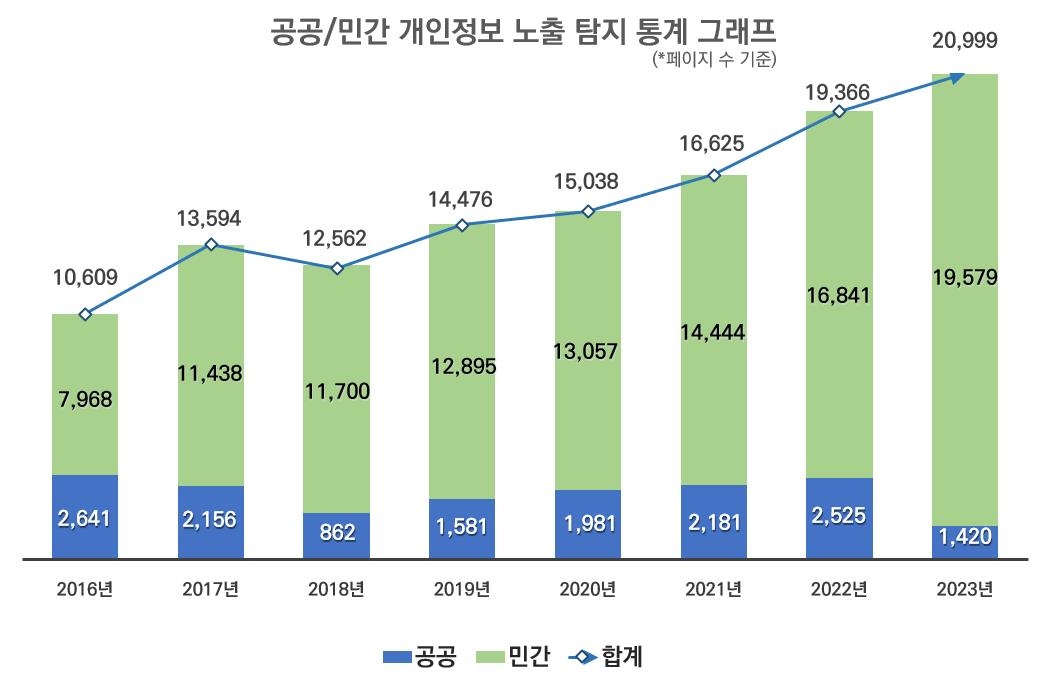
AI 서비스 제공사업자는 인터넷에 공개된 데이터를 AI 모델 학습데이터로 사용하는 과정에서 주민등록번호·신용카드번호 등 한국 정보주체의 중요한 개인정보가 포함될 수 있는 것으로 파악됐다. 한국인터넷진흥원(KISA)에 따르면 지난해 2만999개 페이지에서 주민등록번호, 여권번호 등 개인정보 노출이 탐지됐다.
실제 오픈AI·구글·메타는 학습데이터에서 주민등록번호 등 주요 식별정보를 사전 제거하는 조치가 충분하지 않은 것으로 확인됐다.
개인정보위는 AI 서비스 제공 단계별 보호조치 강화를 요구했다. 또 사전 학습단계(pre-training)에서 주요 개인식별정보 등이 제거될 수 있도록 국민 개인정보 노출이 탐지된 인터넷주소(URL)를 AI 서비스 제공사업자에 제공할 계획이다.
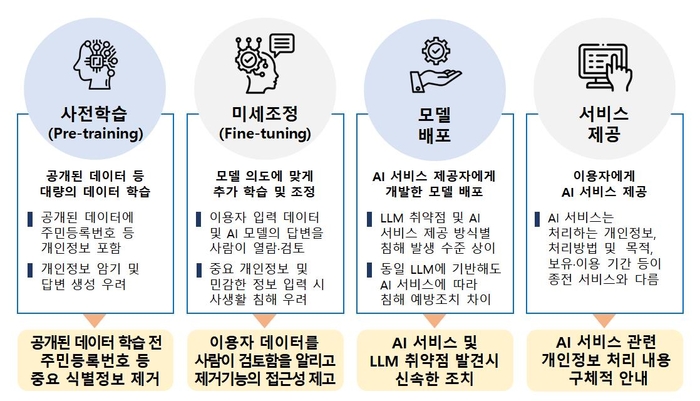
이용자 입력 데이터 처리와 관련해서도 취약점을 확인했다.
LLM 기반 AI 서비스 제공사업자는 AI 모델이 정확한 답변을 하도록 다수 검토 인력을 투입한다. 이용자 관점에선 본인이 입력한 데이터에 대해 검토 인력이 투입되는 '인적 검토'(processed by human reviewer)' 과정 자체를 알기 어렵다. 중요 개인정보 등 민감한 내용을 입력하거나 AI 서비스 제공자가 개인정보 제거 등 조치 없이 해당 정보를 데이터베이스(DB)화할 경우, 사생활 침해로 번질 위험이 있다.
개인정보위는 AI 모델 등 개선 목적으로 이용자 입력 데이터에 대한 인적 검토과정을 거치는 경우 이용자에게 관련 사실을 명확하게 고지하고, 이용자가 입력 데이터를 손쉽게 제거·삭제할 수 있도록 해당 기능에 대한 접근성 제고를 권고했다.
강대현 개인정보위 조사1과장은 “AI 모델의 고도화, 오픈소스 모델의 확산 같은 새로운 AI 기술이나 산업 변화에 맞춰 정보주체의 개인정보를 안전하게 보호할 수 있도록 지속 모니터링하겠다”며 “AI 관련 6대 가이드라인 등 정책방향을 마련하고, 개인정보 강화 기술 개발·보급 등 후속 조치도 차질 없이 추진하겠다”고 덧붙였다
조재학 기자 2jh@etnews.com

