






지난 달 인공지능(AI) 스타트업을 하고 있는 젊은 기업인으로부터 국내에서 AI 학습 모델을 개발하는 일이 얼마나 어려운지를 실감할 수 있는 이야기를 들었다. 그는 “저작권 때문에 AI 학습 데이터를 구할 수 없어서 크롤링(Crawling) 기법으로 신문기사의 댓글 데이터만을 가지고 학습시키다 보니, 욕설·비방·폭언 등 반사회적 표현이 AI 산출물로 나와 당황했다”며 “AI 중소기업에는 양질의 학습데이터 확보를 위한 국가차원의 지원이 절실하다”고 말했다.
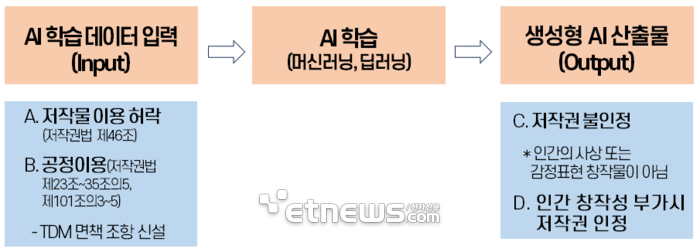
AI 시대 최대 화두 중 하나는 '저작권'이다. 생성형 AI는 학습 데이터 입력(input), 입력 데이터 학습, 생성형 AI 산출(output)의 단계로 이뤄진다. 정확도가 높은 양질의 AI를 만드는 데에는 대량의 양질 데이터가 필요하다. 오픈AI가 개발한 GPT-3.5에는 인터넷에서 크롤링의 방식으로 수집한 4100억개 데이터, 논문보고서 등 웹텍스트 190억개 데이터, 인터넷 기반의 말뭉치 670억개 데이터, 위키피디아 등 인터넷 사전 정보 30억개 데이터 등 방대한 학습 데이터가 사용된 것으로 알려졌다.
생성형 AI는 텍스트, 이미지, 음성 등 형태를 가진 방대한 양의 데이터를 딥러닝(Deep Learning) 기술을 활용해 인간의 창작물과 유사한 산출물을 생성하는 기술이고, 학습에 필요한 방대한 양의 데이터 수집 과정에서 저작권 문제는 불가피하다. 저작물은 저작권자로부터 개별적 이용 허락을 받지 않으면 저작권 침해가 된다. AI 데이터 학습과정에서 대량의 저작물 복제·전송이 이뤄지며, 개별적으로 저작권자의 허락을 일일이 받는다는 것은 사실상 불가능에 가깝다.
◇저작권 적용 예외를 위한 TDM 면책조항 도입 논의:공정이용
예외는 있다. 현행 저작권법(이하 '법')에는 공정이용(fair use)이라고 해 저작권 침해가 면제되는 개별조항(個別條項)을 열거하고 있다. 구체적으로 △공공저작물의 자유 이용(제24조의2) △시사 보도를 위한 이용(법 제26조) △신문, 인터넷 신문 및 뉴스 통신사에 게재된 기사나 논설의 복제·배포·방송(제27조) △공표된 저작물의 인용(제28조) △비영리 목적의 공연·방송(제29조) △도서관 등에서의 복제(제31조) △방송사업자의 일시적 녹음·녹화(제34조) △공표된 프로그램 복제 또는 배포(101조의3) 등 법 제23조에서 제35조의4까지와 법 제101조의3에서 제101조의5까지 총 18개 조항이다.
개별조항에 담을 수 없는 공정이용 사유를 폭넓게 인정하기 위해 우리나라는 2011년 12월 보충적 일반조항(一般條項)으로서 법 제35조의5를 별도로 신설했다. 일반조항은 '저작물의 이용 목적과 성격, 저작물의 종류와 용도, 저작물의 이용이 시장 또는 가치에 미치는 영향 등을 고려하여 저작물의 일반적인 이용 방법과 충돌하지 아니하고, 저작자의 정당한 이익을 부당하게 해치지 아니하는 경우에는 저작물을 이용할 수 있다'고 해 저작권 보호 예외로 하고 있다.
처음에는 AI 학습 데이터 저작권 문제를 제35조의5 일반조항이 해결할 수 있다고 생각했다. 하지만 일반규정 자체가 추상적이어서 AI 개발자에게 충분한 예측 가능성을 제공하지 못하고 법적 안정성 문제가 발생할 것이라고 지적됐다. 그래서 다른 나라처럼 AI뿐만 아니라 '컴퓨터를 이용한 정보분석' 전반에 적용될 수 있는 별도 개별조항, 즉 텍스트·데이터 마이닝(text and data mining:TDM) 면책조항 도입 논의가 시작됐다.
싱가포르는 2021년 적법 접근을 조건으로 TDM 면책조항을 도입하는 법 개정에 성공했고, 일본은 저작물에 표현된 사상 또는 감정을 향수하지 않는 조건으로 상업용 목적도 가능한 TDM 면책조항을 도입했다. 유럽연합(EU)은 '디지털 단일시장 저작권 지침(DSM)' 제4조에서 적법 접근을 조건으로 목적이나 주체 제한없이 상업적 이용도 가능한 저작물 복제·추출 허용하면서 동시에 옵트아웃(opt-out)을 통해 저작권을 유보할 수 있도록 했다.
국내에서는 2021년 '도종환 의원 등 13인의 저작권법 개정안'에 TDM 면책조항을 반영했으나 지금까지 입법화가 지연되고 있다. 이 법안은 적법 접근을 조건으로 저작물에 표현된 사상이나 감정을 향유하지 않는 범위에서 저작물의 복제·전송을 허용하는 내용을 포함하고 있다. 이후 이용호 의원 등 10인, 황보승희 의원 등 10인, 이인영 의원 등 16인 발의 법안도 발의됐으나 모두 외국의 입법례를 벤치마킹한 수준으로 우리나라 AI 시장의 현실을 반영하기에는 부족하다는 평가가 많다.
◇TDM 면책조항 도입과 함께 개별조항도 추가(追加) 보완 필요성
생성형 AI에서 양질의 산출물을 얻기 위해서는 양질의 데이터가 필요하다. 그동안 문화체육관광부와 한국저작권위원회를 중심으로 저작권 문제 해소를 위한 많은 노력이 있었고, 국회에서도 TDM 면책조항 신설에 집중해 왔지만 이보다 좀 더 넓은 시각에서 발상의 전환이 필요하다고 본다. 국가적으로 축적한 방대한 디지털 데이터의 적극 활용 방안 모색과 함께 AI 시장 현실에 초점이 맞춰져야 한다.
현재 국회에 계류되어 있는 TDM 면책조항은 국내 시장의 현실에 부합하도록 수정하는 것이 바람직하다고 본다. 첫째, 크롤링 등 방식의 데이터 수집이 광범위하게 활용되고 있는 현실에서 사전적 적법 접근의 요구는 TDM 면책조항의 취지에 배치될 수 있다. 초기에는 적법 접근을 엄격하게 요구하지 않되, 사후적 옵트아웃으로 적법성을 치유하는 방식을 생각할 수 있다. 둘째, 저작물에 표현된 사상이나 감정을 '향유'하지 않는다는 용어도 지나치게 추상적이어서 법적 안정성이 떨어진다는 의견도 있다. 셋째, 기업의 존재 이유는 수익 창출이다. 그런 의미에서 상업적 사용을 묵시적으로 반영한 '도종환 의원 등 13인의 저작권법 개정안'은 적절하다고 본다.
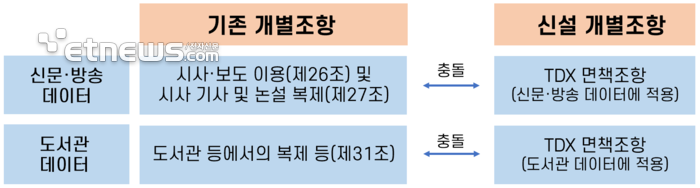
'TDM 면책조항'이라는 새로운 개별조항 신설은 기존 개별조항과의 충돌 또는 배치되는 문제가 생길 수 있다. 따라서 18개 개별조항 각각에 어떻게 TDM 면책조항의 취지를 반영할 수 있는지도 살펴볼 필요가 있다. 예를 들어, 법 제26조와 제27에서에서 신문사와 방송사의 시사보도나 신문·인터넷신문·뉴스통신에 게재된 기사·논설은 타 언론사가복제·배포·방송하는 것이 하용되고 있는 만큼, AI 학습 데이터로 입력하는 것을 공정이용으로 간주해 주는 것도 생각할 수 있겠다. 또, 법 제31조는 도서관 등에서의 저작물 복제를 허용하고 있는데, 도서관 자료는 IMF 외환위기 이후 재정투자로 디지털화되고, 저작권자들도 손쉽게 저작권료 수입을 확보하게 되었다. 이러한 상황을 고려하여 저작권료 면제나 AI 기업이 채산성을 확보할 수 있는 최소 수준의 저작권료를 검토할 수 있겠다.
◇시급한 것은 '저작권에서 자유로운 데이터'부터 기업에 신속 제공하는 일
AI 학습 데이터의 저작권 이슈 해결을 위해서는 발상의 전환이 필요하다. 빠른 시일 내에 우리가 글로벌 AI 강국으로 도약하기 위해서는 정부차원에서 '저작권 이슈가 없는 데이터'의 활용부터 촉진하는 방안을 강구해야 한다.
'저작권 이슈가 없는 데이터'란 첫째, 저작권이 종료된 데이터다. 저작권 보호기간은 통상 저작권자 사후 70년이다. 그 기간이 도과하면 저작권 이슈가 발생하지 않는다. 국립중앙도서관의 전자파일도서 약 133만책, 국회도서관 약 149만책, 한국교육학술정보원(KERIS)의 학위논문, 학술지 등 방대한 분량의 디지털 데이터 중 상당부분은 저작권 보호기간이 종료되었을 것이다. 둘째, 공개된 정치연설, 법정·국회 등에서 공개 진술(제24조), 공표된 공공저작물(제24조의2) 등은 현행법에 의하여도 저작권 제한없이 자유로이 이용할 수 있다. 셋째, 신문·방송 데이터에는 영구보존 데이터도 있지만, 보존기간이 끝나면 폐기되는 것도 많다. 뉴스 및 시사 프로그램은 5~10년, 드라마 및 예능 프로그램은 10~30년, 종이신문 원본은 10~20년이 보존기간이다. 보존기간이 도과되면 폐기되는데 그러한 데이터를 AI 기업이 활용할 수 있도록 하면 좋을 것이다. TDM 면책조항 입법에 앞서 저작권 이슈가 없는 데이터의 활용 촉진을 위한 제도적 장치 마련이 시급하다.
◇저작권 협상 시스템 마련과 중소 AI 기업의 학습 데이터 구입 재정지원
저작권 보호기간이 도과했거나 '저작권 이슈가 없는 데이터'(TDM 면책 조항 포함 개별조항 및 일반조항 등)를 제외한 나머지 데이터는 저적권이 적용되는 데이터일 것이고, 당연히 이용하는 데 저작권료가 수반될 것이다. 현실적으로 AI 기업, 특히 중소·스타트업이 막대한 양의 AI 학습 데이터를 개별 저작권자로부터 구입해 학습시킨다는 것이 가격이나 기술·제도적으로 결코 쉬운 일이 아니다.
이런 문제를 해결하기 위해서 첫째 대규모 저작권에 대한 가격부담을 낮추기 위해 AI 학습 데이터의 수요와 공급을 연결하고 저작권료를 일괄 협상·징수·지급할 수 있는 중개 기구의 제도화에 대한 검토가 필요할 것이다. 둘째 그러한 기구를 통해 시장에서 중소 AI 기업들이 채산성을 맞출 수 있는 수준으로 저작권료를 낮춰야 한다. 셋째 중소 AI 스타트업에 대해서는 '데이터 바우처 사업'의 경우와 같이 '저작권 바우처 사업'을 재정에서 보조한다면 빠른 시일 내에 국내 AI 시장 활성화에 기여할 것이다.
한편, 2023년 12월 27일 문화체육관광부 등에서 발표한 '생성형 AI 저작권 안내서'에서 제시된 바와 같이 AI 기업이 학습 데이터의 저작권 위반 여부를 사전에 필터링하거나, 산출물을 활용하거나 인용할 때 AI 기업이 그 출처를 기재하는 등의 사전적(事前的) 규제는 기업에게 과도한 부담을 안기는 만큼 바람직하지 못하다고 본다. 굳이 필요하다면 저작권 침해 확인 시스템을 통해 저작권자가 그 권리의 침해를 확인할 수 있도록 사후적(事後的) 규제를 강화하고, 한국저작권위원회 등에 조정, 또는 중재 및 소송 등 필요한 조치를 취할 수 있도록 하면 될 것이다.
송병선 한국데이터산업협회(KODIA) 회장 bssong1@gmail.com
〈필자〉 행정고시 30회로 경제기획원에서 공직을 시작해 기획예산처 정보화예산팀장, 재정개혁2과장, 산업정보예산과장, 기획재정부 연구개발예산과장, 기획재정담당관, 주뉴욕 재정경제금융관, 국유재산심의관, 대통령직속 지역발전위원회 기획단장 등을 역임하고 한국기업데이터 대표이사 사장을 거쳐 지난해 5월 한국데이터산업협회 2대 회장에 취임했다.
