






최근 유튜브에 들어가면 꼭 보는 동영상이 생겼어요. 바로 인공지능(AI) 기술로 만들어진 ‘AI 커버곡’이에요. 좋아하는 가수 중 하나인 아이유가 부른 뉴진스 ‘디토(Ditto)’ 영상을 처음 봤을 때 너무 신기했는데요. 아이유의 실제 목소리와 창법도 똑같고, 자연스러웠기 때문이죠.
그 이후로도 유튜브 알고리즘으로 여러 AI 커버곡을 듣게 됐습니다. 계속 반복해서 듣다 보니 나도 만들 수 있을까라는 생각이 들더라고요. 그래서 직접 만들어보기로 결심했습니다.
AI 커버곡, 세 단계로 만들자

본격적으로 AI 커버곡 제작에 앞서 간단한 절차를 소개해 드리고자 해요. AI 커버곡이 하나의 툴만 사용해서 뚝딱 만들어지면 좋겠지만, 생각보다 여러 툴을 사용해야 하더라고요.
먼저 ⓛ음원에서 가수 목소리와 MR을 분리하고 ②AI 기술로 가수 목소리를 변환해 준 뒤 ③분리했던 MR과 AI로 변환한 목소리를 합치면 모든 과정이 끝납니다. 손에 익숙해지면 깨나 그럴듯한 결과물이 나왔죠.
구체적인 과정은 아래에서 설명하겠습니다. 참고로 저는 목소리를 바꿔줄 음원으로 가수 신예영의 대표곡인 ‘우리 왜 헤어져야 해’를 선택했고, 목소리는 걸그룹 에스파의 ‘윈터’ 목소리를 적용해봤어요.
ⓛ가수 목소리와 MR 분리하기
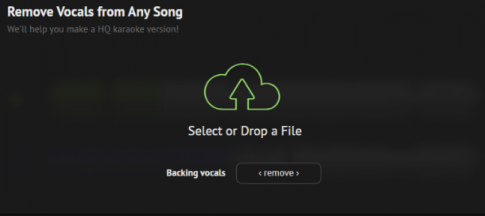
첫 번째 단계는 AI 커버곡에 필요한 ‘MR’과 ‘목소리’를 각각 분리하는 단계예요. 별도 파일로 만들어야 하는 이유는 단계에 따라 분리된 파일이 필요하기 때문입니다. 목소리 파일은 바로 다음 단계에서 AI를 통해 다른 목소리로 변경해야 하고, MR 파일은 마지막 단계에서 AI로 변환된 목소리와 병합할 예정이죠.
‘MR’과 ‘목소리’를 분리해 주는 툴은 많았는데요. 요청하는 횟수에 제한 있는 서비스나 직관적이지 못한 툴은 제외하기로 했어요. 그렇게 ‘X-마이너스 프로(X-MINUS PRO)’ 웹 사이트에서 제공하는 툴을 사용하기로 했죠. 로그인하지 않아도 되고, 1분 남짓한 시간만 기다리면 분리된 MR과 목소리 개별 파일을 받을 수 있었어요. 단 단기간 내 여러 차례 요청하면 몇 분간은 사용에 제한이 있을 수 있으니 유의해야 합니다.
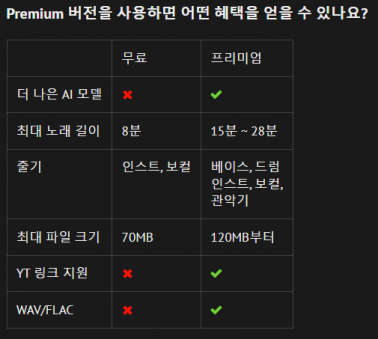
유료 결제 시 더 나은 AI 모델로 분리가 가능하다고 하긴 하더라고요. 최대 지원되는 노래 길이도 늘어나고요. 단순 목소리와 MR 이상 다양한 분류(베이스, 드럼, 관악기 등)에 따라 음원도 분리해 주죠. 만족스러운 결과를 얻고 싶다면 한 번쯤 고민해봐도 좋을 듯 해요.
저는 결제하지 않고 기본 옵션 그대로 파일을 저장해줬습니다. 초록 색상 구름 모양 아이콘을 누르면 열리는 파일 선택 창에서 MP3 전체 음원 파일을 선택합니다. 그 후 초록색 ‘Instrumental’과 보라색 ‘Vocals’ 버튼을 눌러 ‘MR 파일’과 ‘목소리’ 파일을 각각 저장해주면 돼요.
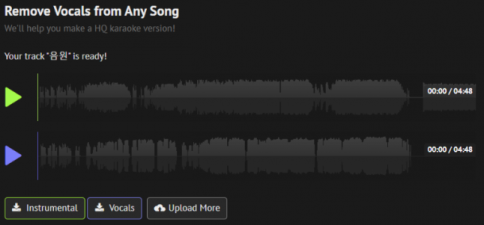
파일명은 헷갈리지 않게 바꾸는 걸 추천드려요. 파일이 늘어나면 헷갈릴 수도 있거든요. 저는 원곡 파일명은 ‘음원’, 분리된 MR 파일명은 ‘MR’, 분리된 목소리 파일명은 ‘목소리’로 바꿔줬어요.
②AI 툴로 목소리 변환하기
이제 분리한 ‘목소리’ 파일을 AI 툴로 변환할 차례예요. 이를 위해서는 적용할 음성 모델이 필요해요. 목소리를 변환하는 AI 툴들은 모두 관련 음성 모델을 제공하고 있어요.
다만 AI 음성 변환 툴 대부분이 유료라서 무료로 원하는 가수의 목소리 음성 모델을 구하는 데는 어려움이 있었어요. 게다가 무료 툴 대부분은 사용 가능한 횟수가 제한적이었어요. 그래서 그중 가장 제한 횟수가 적고, 알 만한 K-POP 음성 모델을 제공하는 ‘Musicfy’를 사용했습니다.
‘Musicfy’는 로그인 시 하루 최대 5번까지 사용할 수 있어요. 무료 툴 중 가장 많은 횟수로 사용할 수 있었던 것 같아요. 음성 모델 종류가 많지는 않았지만, 방탄소년단(BTS) 뷔(V), 에스파 윈터 등 주요 K-POP 가수의 일부 음성 모델을 얻을 수 있었죠.
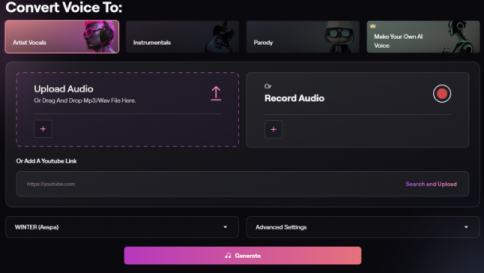
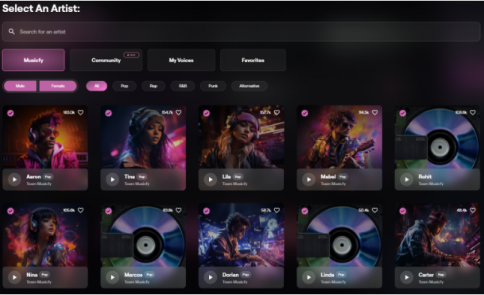
‘Musicfy’ 웹사이트에 접속한 후 ‘아티스트 선택(Select an Artist)에서 ‘윈터’ 음성 모델을 선택해 줬습니다. 페이지 전반적으로 이미지나 한글이 없어 음성 모델을 선택할 때 어려움이 있었는데요. 그럴 때는 영어 이름을 웹사이트에 검색하거나 하단 재생 버튼으로 목소리를 들어줍니다. 그러면 가끔 익숙한 목소리가 나올 때도 있더라고요.
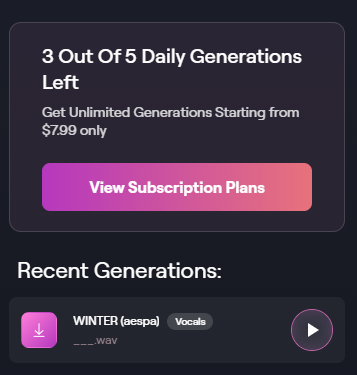
그 이후에는 오디오 업로드 부분에 신예영의 목소리만 있는 ‘목소리’ 파일을 업로드해줍니다. ‘생성(Generate)’ 버튼을 누른 후 잠시 기다리면 맨 오른쪽 하단 ‘다운로드’ 버튼이 보입니다. 이를 눌러주면 윈터 목소리가 부른 ‘우리 왜 헤어져야 해’ 노래가 저장됩니다. 파일명은 ‘AI 목소리’로 바꿔줬어요.
③하나로 합쳐보자

벌써 마지막 단계인데요. 이제 AI로 만든 윈터 AI의 목소리와 음원 MR을 다시 하나로 합쳐줄 거예요. 저는 ‘골드웨이브’라는 툴을 사용했습니다. 다른 툴을 실행해보니 이어붙이는 방식만 가능하더라고요. 목소리 파일 뒤에 MR 파일이 이어지는 식으로요. 근데 골드웨이브는 몇 번 클릭만으로 하나의 곡으로 간편하게 합칠 수 있었어요.
툴을 PC에 설치한 후 저장된 윈터 AI 목소리와 음원 MR 파일을 모두 추가합니다. 그러면 두 개의 사운드 트랙이 추가되는데요. 여기서 한 가지 팁이 있습니다. 파일을 추가하자마자 뜨는 화면이 사운드 트랙 두 개가 붙은 상태여서 복잡해 보이더라고요. MR과 목소리 각각의 사운드 트랙이 한눈에 확인될 수 있게 중간에 틈을 만들어줄 거예요. 각 사운드 트랙 창 테두리를 마우스로 길게 드래그해서 크기를 조정해줍니다.
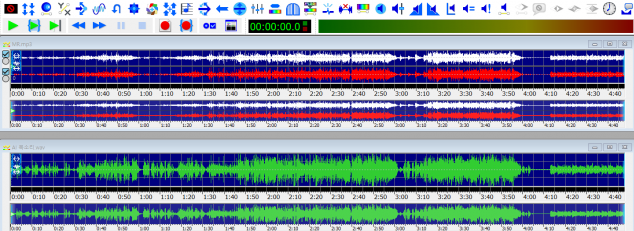
이제 본격적으로 두 목소리를 하나로 합쳐주면 됩니다. 배경음 위에 목소리가 얹어지도록 MR 먼저 선택한 후 목소리를 선택해줘야 합니다. 저는 작업 중 헷갈리지 않게 위에 MR 사운드 트랙을, 아래에 목소리 사운드 트랙을 배치할 거예요. MR 사운드 트랙 파일을 선택한 후 오른쪽 마우스를 누르면 ‘복사(Copy)’가 보일텐데요. 그 후 선택하지 않았던 다른 트랙 파일(저의 경우 아래에 있는 파일)을 선택한 후 상단 메뉴 ‘편집(Edit)’에서 ‘믹스(Mix)’를 선택해줍니다.
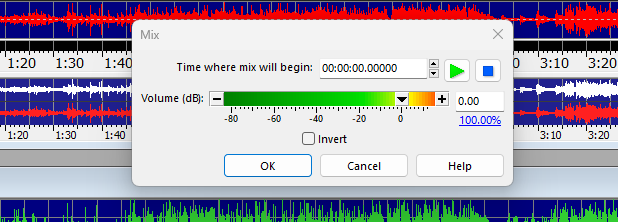
그러면 ‘믹스가 시작되는 시점(Time where mix will begin)’을 묻는 창이 뜰거예요. 목소리와 MR은 곡이 시작하는 처음부터 섞여야겠죠. 이를 위해서 ‘00:00:00.00000’로 반드시 지정해 주도록 합니다. 초반에 이 부분에서 실수를 해서 다시 만들어줘야 했어요.
초록색 재생 버튼을 누르면 믹스된 결과를 미리 들어볼 수도 있는데요. 두 파일이 성공적으로 믹스된 걸 확인했다면 파일 메뉴에서 ‘저장(Save)’을 눌러 파일을 저장하면 완성입니다.
만족스럽지만 아쉽기도 해

완성 후 들어보니 윈터의 독특한 목소리와 창법이 그대로 반영된 것 같아서 신기했습니다. 다만 고음이 등장하는 노래 후반부로 갈수록 갈라지는듯한 기계음이 나타났는데요. 그런 점을 제외하면 실제 윈터의 목소리가 잘 녹아들었다는 점은 만족스러웠습니다.
물론 시행착오도 있었는데요. 원곡이 선명하지 않을 수록 인공지능 목소리는 정확하게 적용되지 못했고요. 남성 목소리에 여성의 곡을 입히려고 해도 제대로 적용되지 않았어요. 특히 영어를 주로 사용하는 유명 해외 정치인 목소리로 AI 변환한 건 한국말을 알아들을 수 없을 정도로 뭉개지기도 했죠. 무료이기 때문에 한계가 있었을 수도 있겠지만, 인공지능 툴 자체의 기능적인 한계도 분명히 있다는 생각이 들더라고요.
만약 유료 툴을 사용했다면 더 좋은 결과가 나왔을지도 모르겠네요. 여러 작업으로 완성되는 과정이 번거롭기도 했는데요. 그래도 인공지능 툴을 사용했기 때문에 많은 과정을 생략하고, 시간도 단축할 수 있었어요.
AI 커버곡을 만들 때 주의점

AI 커버곡을 만들려면 기존 가수의 목소리가 담긴 원곡 파일이 필요합니다. 그러나 AI로 무분별하게 창작물을 만드는 사례가 꾸준히 늘고 있어 주의해야 하는데요. 아직 AI 커버곡을 처벌하기 위한 명확한 법적 기준이 마련되지는 않았지만, 관련 데이터를 함부로 활용하는 행위 자체를 엄연한 저작권 침해로 보는 시각이 지배적인 편이에요.
특히 지난 12월 유튜브는 유행처럼 번져가는 ‘AI 커버곡’을 단속하기 위해 AI 생성 콘텐츠에 관련 표시를 의무화하는 새로운 가이드라인을 도입하기도 했어요. AI 콘텐츠를 위해 무단 사용 후 업로드 시 복제권, 실연권, 공중송신권 등 다양한 법적 침해 우려가 있다고 하죠.
사용해 볼 수는 있지만 이를 공유하거나 수익화하지 않도록 주의해야 해요. AI 커버곡을 직접 제작해 보면서도 이 점을 계속 염두에 뒀었는데요. 법적 침해 여부가 인정될 수 있다는 점을 항시 인지하는 것이 중요할 것 같아요.
테크플러스 최현정 기자 (tech-plus@naver.com)