






디노티시아는 오픈소스 플랫폼 '허깅페이스'를 통해 한국어 논리 추론에 최적화된 대형언어모델(LLM) 'DNA-R1'을 공개했다고 6일 밝혔다.
DNA-R1은 140억개(14B)의 파라미터를 갖고 있으며 한국어로 추론 전 과정을 출력한다. 문장 생성과 번역은 기본적으로 제공하며 △수학문제 해결 △코드 작성 및 디버깅 △논리적 사고 및 분석 △한국어 문맥 이해 등 고차원적인 작업도 수행할 수 있다.
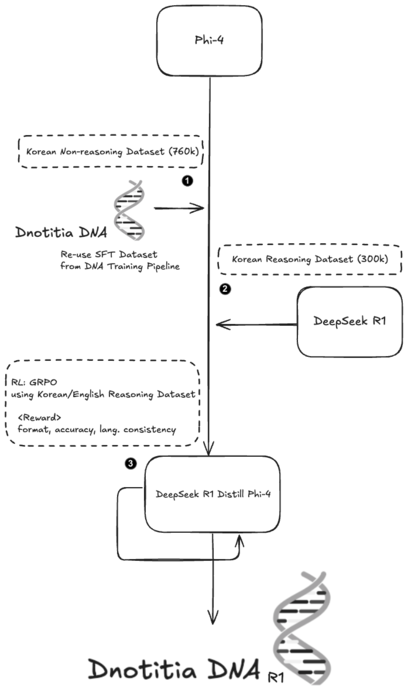
디노티시아는 DNA-R1에 3단계의 학습 프로세스를 적용했다. 먼저 대량의 한국어 데이터를 학습해 문장 이해 능력을 확보했으며, 이후 논리적 사고에 특화된 데이터를 추가 학습시켜 문제 해결 능력을 높였다. 마지막으로 AI가 스스로 정답을 도출할 수 있도록 보상 학습 기법을 적용, 한국어·영어로 보다 정확하고 일관된 응답을 생성할 수 있도록 강화 학습을 진행했다.
경쟁 모델 대비 객관적으로 뛰어난 성능도 갖췄다. 한국어 AI 성능 평가 지표인 'KMMLU2' 벤치마크에서 59.9%를 기록하며, 기존 동급 모델 (50.50%) 대비 약 18.6% 성능 향상을 입증했다.
정무경 디노티시아 대표는 “지난 12월 챗GPT 'O1' 출시 이후, AI 서비스의 패러다임이 단순한 응답 생성에서 논리적 사고에 기반한 추론으로 급격히 전환되고 있다”며 “회사는 빠르게 한국어에 최적화한 추론 모델을 내놓으며 글로벌 AI 기업들과의 기술 격차를 좁혀가고 있다”고 강조했다.
박진형 기자 jin@etnews.com

